I was surprised by the amount of surprise in the technology community when Google recently announced that its RankBrain artificial intelligence (AI) is being used to help understand natural language queries and serve results. This shouldn’t surprise anyone. Google has always been an AI company.
This statement from Larry Page is about as clear as it gets (emphasis mine).
Around 2002 I attended a small party for Google—before its IPO, when it only focused on search. I struck up a conversation with Larry Page, Google’s brilliant cofounder… “Larry, I still don’t get it. There are so many search companies. Web search, for free? Where does that get you?”… But Page’s reply has always stuck with me: “Oh, we’re really making an AI.”
For most people, the term “AI” tends to conjure up ideas of an all-knowing computer program that understands humans completely, and returns answers in a context that is immediately understandable to humans, like the Star Trek computer.
At SXSW in 2013, Google’s Head of Search, Amit Singhal said:
“The destiny of search is to become that ‘Star Trek’ computer and that’s what we are building.”
In fact, Singhal recently demoed a Star Trek-like lapel pin that interacts via voice with Google Now.
Even if you don’t take public statements and product demos very seriously, you can simply look at where Google has been investing in creating IP.
Here’s a count of research papers published by Google. You’ll notice that Artificial Intelligence & Machine learning have 143% more published papers than areas like Information Retrieval & the Web, which is at the core of traditional approaches to search.
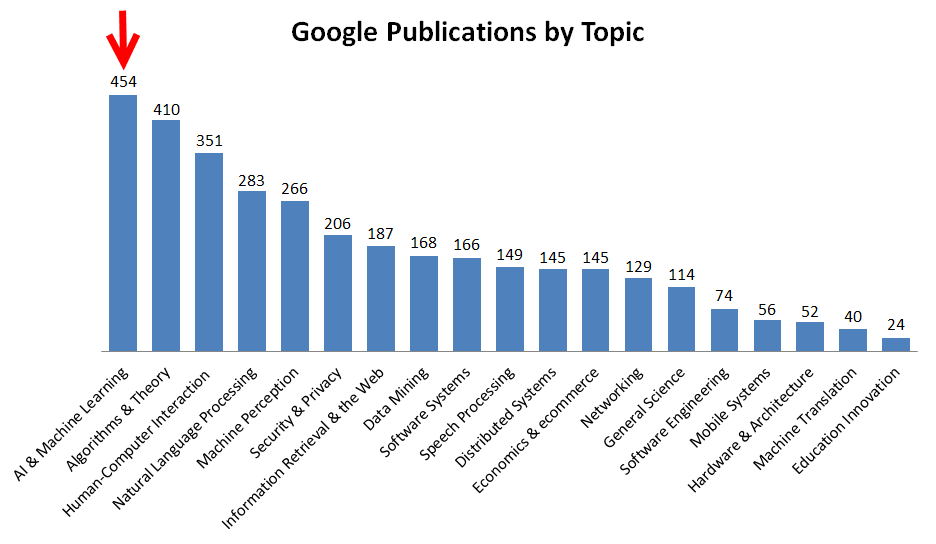
However, despite this massive amount of AI and machine learning (ML) work being done at Google, it’s just in the last year that RankBrain is being used to help field queries.
Google have been working actively on AI & ML in relation to search for a long time now (in Internet years). In 2008, Anand Rajamaran had a discussion with Peter Norvig (former Director of Search Quality at Google and author of Artificial Intelligence: a Modern Approach) about ML (emphasis mine).
“The big surprise is that Google still uses the manually-crafted formula for its search results. They haven’t cut over to the machine learned model yet. Peter suggests two reasons for this. The first is hubris: the human experts who created the algorithm believe they can do better than a machine-learned model.The second reason is more interesting. Google’s search team worries that machine-learned models may be susceptible to catastrophic errors on searches that look very different from the training data. They believe the manually crafted model is less susceptible to such catastrophic errors on unforeseen query types.”
And this has been corroborated by other sources. A former Google Search Quality engineer had this to say on Quora in 2011 (emphasis mine):

I want to call out this sentence in particular (emphasis mine):
“In a machine learning system, it’s hard to explain and ascertain why a particular search result ranks more highly than another result for a given query. The explainability of a certain decision can be fairly elusive.“
This is a result of how machine learning models work. ML models optimize for accurate predictions, and don’t have any mechanism to explain why they are accurate. From HBR:
“One important difference from traditional statistics is that you’re not focused on causality in machine learning.”
This is very important. ML models are just interested in the best result, not an understandable explanation of how each ingredient in the recipe contributes to making that recipe so delicious.
ML models decide what variables to use, and sometime build their own variables called “features” in order to make better predictions.
“Think of “feature extraction” as the process of figuring out what variables the model will use. Sometimes this can simply mean dumping all the raw data straight in, but many machine learning techniques can build new variables — called “features” — which can aggregate important signals that are spread out over many variables in the raw data. In this case the signal would be too diluted to have an effect without feature extraction.”
This leads to the “black box” problem that Edmond Lau pointed out. ML models can build their own synthetic metrics, and do not explain causally why a particular combination of metrics leads to a better result.
From Amit Singhal’s perspective, this leads to team that lacks “direct control” of its own algorithm, which makes it harder to intentionally shape its direction based on inputs that make sense to humans.
Fundamentally, this is because machines do not “think” in the way that humans do. The problem with the label “Artificial Intelligence” and batting around reference to the Star Trek computer is that we anthropomorphize these computer systems and want them to be like human minds. We created them, so in a way they’re just mimicking us, right?
Wrong, of course. Machines execute a series of operations until the program tells them to stop. Machines don’t “think” the way we do, but that won’t stop them from doing things that astound us. What an AI needs is massive data to learn from, and massive computing power to crunch it all, and Google has both.
Andrew Ng, who has taught AI at Stanford, built AI at Google, and then moved to Baidu to continue developing AI, recently said:
“When machines have so much muscle behind them that we no longer understand how they came up with a novel move or conclusion, we will see more and more what look like sparks of brilliance emanating from machines.”
Right now, Google’s AI isn’t really being given that chance. It’s essentially being asked to work clean-up duty on all the completely new / novel and hard-to-understand queries that Google sees in a given day. From Bloomberg:
“The system helps Mountain View, California-based Google deal with the 15 percent of queries a day it gets which its systems have never seen before.”
This isn’t glamorous work, but it doesn’t need to be. The AI doesn’t care. What it does is learn. A “learning machine” creates a positive feedback loop (as it learns, it discovers way to accelerate learning). From Demis Hassabis, CEO of deep learning company DeepMind (acquired by Google in 2014 for $400MM):
“I also think the only path to developing really powerful AI would be to use this unstructured information. It’s also called unsupervised learning— you just give it data and it learns by itself what to do with it, what the structure is, what the insights are. We are only interested in that kind of AI.”
RankBrain is just the tip of the AI iceberg. As we’ve seen, Google has thought of itself as an AI company from the beginning, but, they’ve been cautious in their use of AI. And we know that their ambitions are toward a much more powerful and self-directed AI. The fact that RankBrain has advanced sufficiently to be included in Google’s ranking algorithm is a big step, but it’s just the beginning.
Google is in a uniquely powerful position in the AI field. They have massive data and massive computing power. Put the two together and very interesting things can happen. It may seem like a big leap to get from typing queries into a search box to speaking to an omniscient Star Trek computer that understands every word we say and the context around it. But we’re much closer than you think.